Acknowledgements
The following knowledge about git submodule usage has been achieved from on-site training with Adam Dymitruk. (Also, be sure to check out Adam's article in Code Magazine: Git from a Developer's Perspective.)
What scenario is this blog entry meant to address?
This blog entry addresses the common scenario where multiple web, Windows, Silverlight, console, or other clients all reference a common set of backend libaries. The backend libraries would contain the domain model, repository layer, utils, external gateway references, and so on.
Why git submodules?
git submodules present a distinct advantage over other methods for referencing backend libraries. Let's look at some of the alternate approaches generally used.
Approaches for referencing backend libraries from multiple clients
- Referencing compiled DLLs (via file directory or GAC).
- Referencing a web proxy (where backend libraries are deployed via a web services layer).
- Referencing the .csproj files from a single location in your file directory
- Referencing the .csproj files from multiple locations (one per local git repository)
Let's have a more detailed look at each approach:
Referencing compiled DLLs
In this case, you treat the backend libraries as a somewhat fixed SDK, much as you might treat a 3rd party library. In debug mode, your breakpoints end at the boundary of the compiled DLL.
Referencing a web proxy
You build a Remote Facade over the domain, in which all possible domain interactions are encapsulated in coarse-grained service methods. You then expose this layer as web services, and in your clients, create web services proxies, which you then reference. In debug mode, your breakpoints end at the boundary of the web service proxy.
Referencing the .csproj files from a single location in file directory
You wish to debug right from the client through to the backend, so you reference your backend libraries in two distinct ways:
- In standard fashion, you have a solution file for the backend libraries themselves, within the enclosing folder. This solution also includes various unit/integration test projects for building / validating your backend libraries.
- However, your external clients ALSO reference one or more of the library/projects as .csproj files, within your local client solution file.
Which brings us to the 4th approach:
Referencing the .csproj files from multiple locations (one per local git repository)
The following diagram demonstrates the file directory configuration for this approach:

In this last scenario, each local git repository (a grouping of client projects, based on some common organizing principle determined by your organization) has a local copy of the backend libaries stored WITHIN that local repository. The benefit provided is that each copy of the backend libaries can exist in a different state (i.e. at a different point in the git commit history, pointing at a different branch.)
Here's what that might look like for you on some future Tuesday at work:
- In the morning, you are working on the SilverlightClientApps local repository, on ClientApp2. For this you require the backend libaries in release1.8 branch.
- In the afternoon, you are working on the WebClientApps local repository, on ClientApp5. for this you require the backend libraries in hotfix_2010Oct branch.
Steps to setup a git submodule
Let's assume you are starting by installing git. We'll then make 3 local libaries: WebApps, WinApps, and BackendLibaries. We'll turn each one into a git repository, store them all in a fake local server (which is good enough for our purposes at the moment), and then setup additional local copies of the BackendLibaries as submodules with distinct commits, in each local repository (i.e. WebApps and WinApps).
Do the following:
- Install git if you don't have it already installed.
- Launch GitBash.
- Create a local directory called /c/dev/
- As per the following screenshot, set up myGitSubmoduleDemo with 3 subdirectories for webApps, winApps, and backend Libraries

- Go to the webApps subdirectory, and set it up as a local git repository, with a single commit, and set to the dev branch:

- Repeat for the winApps directory

- And finally, repeat for the backendLibraries, but with 2 release branches
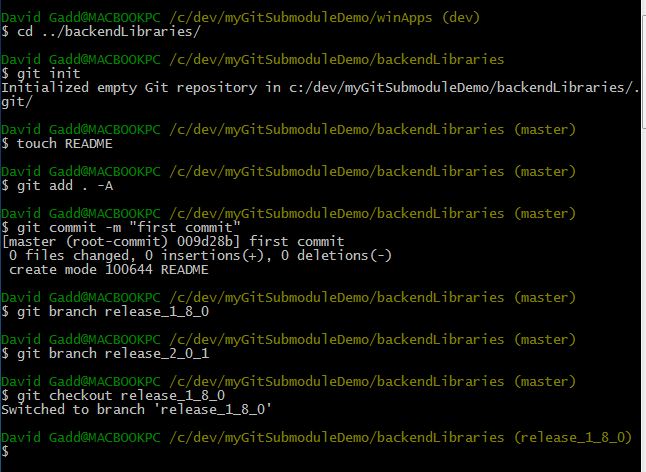
- Next: you need to set up all 3 local repositories as server repositories. In this example, you simply create a local directory at /c/MyFakeGitRepositoryServer/, and make a bare clone of each local repository in this location.
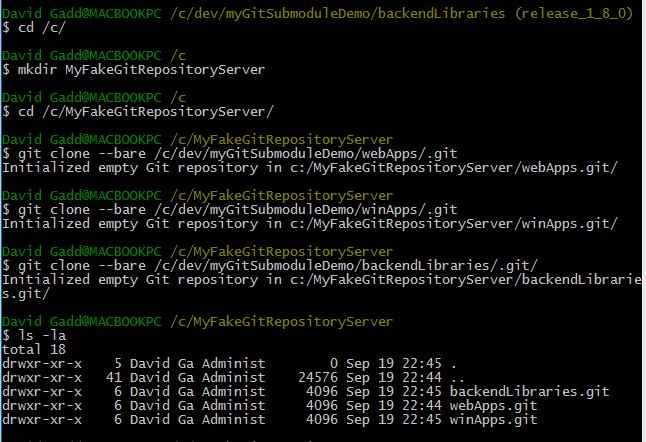
- Now return to your local repositories, and use the "git remote add origin" command to connect your local repository to each server repository
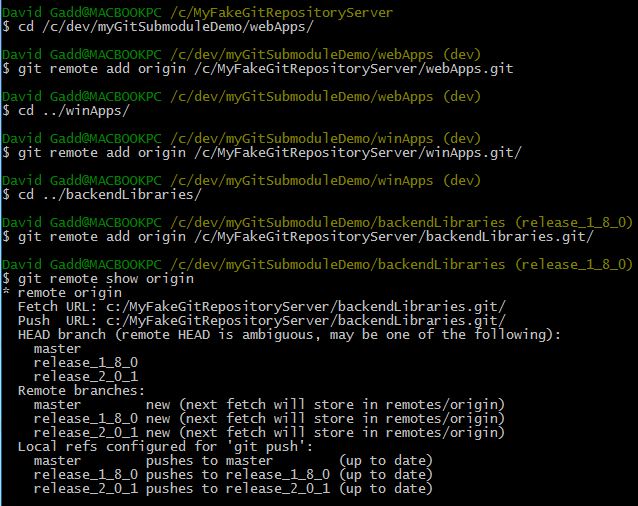
- Congratulations! You are now ready to create a submodule within each client repository (webApps and winApps). Let's start by creating the submodule within webApps

- Note that in the last step, you change directory from the outer directory, "webApps" to the inner directory (the submodule) "backendLibraries". Notice that these directories are in completely different branches. Other than relative placement, they are INDEPENDENT. You can edit either the outer client repository or the inner submodule, you could add commits to either one, change branches, or do any other git action should you choose; but these are independent local repositories, and your actions in each are separate and independent.
- Now let's repeat the above steps for the "winApps" local repository:

- And finally, just to make the point perfectly clear: let's make a NEW branch on this copy of backendLibraries, add a new file within this branch, and commit it:
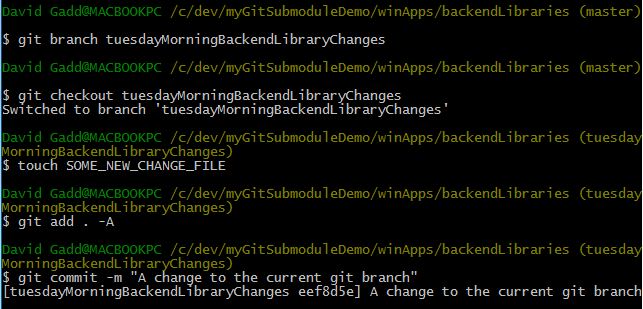
- Note that this new branch is on the backendLibraries submodule, WITHIN winApps. The enclosing local repository winApps is unchanged (still within dev branch). Go up one level to the winApps branch, and type "git status" to check your status.

- The git status commands does observer some changes, but these are all EXTERNAL changes, about the submodule itself: it sees that a submodule has been added (along with a .gitmodules configuration file); and it can tell that backendLibaries has been modified. But it knows nothing about the changes within the backendLibraries submodule, because that is not within its scope. You are now managing, two, separate local repositories, one of which happens to be nested as a submodule within the other.
Does having two, independent copies of the backendLibaries in each local repository remind you of anything? It should: this scenario is indistinguishable from having two developers, on two separate machines doing branching, commits, merges, and checkins (git push) on local copies of backendLibraries. It just happens that in this case, those two local developers are both YOU: you, in the morning, working on some webApps and the backendLibraries submodule within webApps; and you, in the afternoon, working on some windowsApps and the backendLibraries submodule within windowsApps.
In conclusion, the main benefits of git submodules (as implemented in the above scenario) are twofold:
- You can use direct .csproj references to your backend Libraries in your client apps.
- You can maintain independent (and diverging) branches of those backend Libraries in each local git repository that you configure with a backendLibraries submodule.